목차
[Python으로 MySQL접속해서 쿼리해보기]
1. 연결, 종료
2. 쿼리 투입
3. Fetch All
[Python with csv]
Python으로 MySQL 접속
[1. 연결, 종료]
실습환경만들기
1. 터미널에서 가상환경 만들기(ds_study)
conda create -n ds_study python=3.8. #가상환경 생성하기
conda activate ds_study #가상환경 진입하기
vscode 혹은 Web browser를 통해 실행하고, ds_study환경에서 작업
모두 sql_ws폴더에서 시작 [실행위치]
[백업 후 데이터삭제]
mysqldump ~
use newdb;
delete from police_station;
vscode에서 python.ipynb파일 만들고, ds_study환경으로 세팅(?)
[MySQL Driver설치]
pip install mysql-connector-python
SQL 접속하는 코드 문법
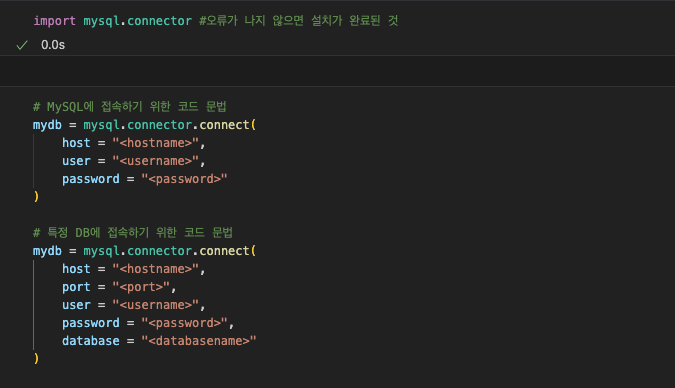
1. Local Database 연결 예시

2. AWS RDS (database-1) 연결 예시

사용을하다가 사용이끝났으면, 종료를해줘야함. 연결종료 나중에 연결너무많아짐.
local.close()
remote.close()
[2. 쿼리 투입]
Query를 실행하기 위한 코드 문법


( test03.sql 생성 : CREATE TABLE sql_file(id int, filename varchar(16)); )
SQL File 내에 Query가 여러개 존재하는 경우




[결과확인] select* from sql_file;
[3. Fetch All]
쿼리를 실행한다음에 결과값이 로우를 포함하고 있으면 fetch all을 썼었음



[실습]



Python with csv
제공받은 police_station.csv를 Pandas로 읽어와서 데이터를 확인합니다.
Import pandas as pd
Df = pd.read_csv(‘police_station.csv’)
테이블에 넣어줄거임

읽어올 양이 많은 경우, cursor 생성시 buffer 설정을 해준다.
cursor = conn.cursor(buffered=True) #select쓸게 아니라서 buffered옵션 안해도됨
sql = “INSERT INTO police_station VALUES (%s, %s)” #insert문 만들기
commit()은 database에 적용하기 위한 명령
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit() #이래야 적용이 됨(db에 들어감)
[결과 확인]
cursor.execute(“SELECT * FROM police_station”) #이거할거면 buffered 옵션 필요
result =cursor.fetchall()
for row in result:
print(row)
pd.DataFrame(result)
crime_status테이블에 2020_crime.csv데이터를 입력하는 코드 작성
AWS RDS에서 작업할거니까 접속.





위 교육 자료는 zerobase로부터 제공받아 작성되었습니다.
'📊 DATA ANALYSIS > 스터디노트' 카테고리의 다른 글
| [스터디노트] Remote Repository (0) | 2024.05.17 |
|---|---|
| [스터디노트] 카드거래이력 분석을 통한 고객특성파악 (0) | 2024.05.17 |
| [스터디노트] VCS 및 Git 설정 (0) | 2024.05.15 |
| [스터디노트] 고객 Segmentation을 위한 RFM분석 (0) | 2024.05.14 |
| [스터디노트]Git Log 쓰임 및 예제로 이해해보기 (0) | 2024.05.14 |