상황
최근 이직 시장이 활발하게 성장함에 따라 A사에 직원들도 줄줄이 퇴사 행렬을 이어가고 있다.
핵심인재의 유출이 지속되고 있어 회사 입장에서는 큰 문제에 봉착했다.
HR팀은 이를 해결하기 위해 이직 가능성이 높은 핵심인재를 대상으로 관리 프로그램을 운영하려고 한다.
목적
이직 직원수 감소, 핵심인재 방어, 업무 로드 평준화
데이터 구조
| Age | Attrition | BusinessTravel | DailyRate | Department | DistanceFromHome |
| 나이 | 이직여부 | 출장 | 일당 | 부서 | 집까지의거리 |
| Education | EducationField | EmployeeCount | EmployeeNumber | EnvironmentSatisfaction | Gender |
| 교육수준 | 전공 | 직원수 | 직원번호 | 환경만족도 | 성별 |
| HourlyRate | JobInvolvement | JobLevel | JobRole | JobSatisfaction | MaritalStatus |
| 시급 | 업무 몰입도 | 업무레벨 | 업무역할 | 업무만족도 | 결혼여부 |
| MonthlyIncome | MonthlyRate | NumCompaniesWorked | Over18 | OverTime | PercentSalaryHike |
| 월소득 | 월급 | 과거회사경험횟수 | 18년이상 | 야근여부 | 급여인상률 |
| PerformanceRating | RelationshipSatisfaction | StandardHours | StockOptionLevel | TotalWorkingYears | TrainingTimesLastYear |
| 고과 | 인간관계만족도 | 평균근무시간 | 스톡옵션레벨 | 총 경력 | 작년 훈련횟수 |
| WorkLifeBalance | YearsAtCompany | YearsInCurrentRole | YearsSinceLastPromotion | YearsWithCurrManager |
| 워라벨 수준 | 현 회사 근무년수 | 현재 업무 년차 | 마지막 승진일로부터 년차 | 현재 팀장함께한 년차 |
1,470행, 35열의 데이터 (매우 적네..)
분석과정 요약
1. EDA(이직 현황 탐색)
2. 가설 수립 및 검증
3. ML 활용 이직 직원 예측
-모델 학습 및 평가
-중요 변수 파악 및 1위 변수 탐색
1. EDA(이직 현황 탐색)
df.shape #행,열 수 확인
df.info() #data type 확인
df.isnull().sum() #결측치 확인
df.describe() #이상치 확인
- Attrition 컬럼의 value_counts()를 활용해 이직률 파악 (약 16%)
- Attrition 컬럼을 모델에서 해석할 수 있도록 1과 0으로 변환
df['Attrition'] = np.where(df['Attrition']== 'Yes', 1, 0)
- 연령별, 성별, 부서별 이직률 현황 도출


2. 가설 수립 및 검증
가설1. 업무만족도는 높으나 인간 관계로 인한 이직률이 높을 것이다.
가설2. 근속년수 대비 같은 업무를 한 비중이 높다면 이직률이 높을 것이다.
가설3. 야근을 많이 해도 급여인상률이 높다면 이직률이 낮을 것이다.
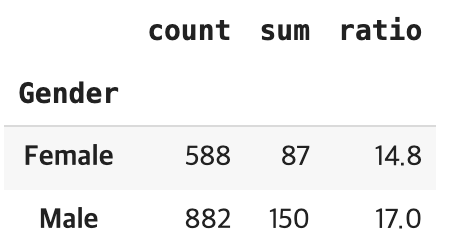
가설1) 업무만족도는 높으나 인간관계로 인한 이직률이 높을 것이다.
#'JobSatisfaction', 'RelationshipSatisfaction', 'Attrition' 컬럼 활용
df_gp = df.groupby(['JobSatisfaction'])['Attrition'].agg(['count','sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1
df_gp2 = df.groupby(['JobSatisfaction', 'RelationshipSatisfaction'])['Attrition'].agg(['count','sum'])
df_gp2['ratio'] = round((df_gp2['sum'] / df_gp2['count']) * 100, 1)

- 업무 만족도별 이직률 현황, 업무만족도가 낮을 수록 이직률이 높다.
- 업무만족도가 높은 직원은 인관관계에 따라 이직률에 영향을 덜 받는것으로 보이고, 업무만족도가 낮은 직원은 인관관계가 나쁠수록 이직률이 증가하는 경향이 보인다.
가설2) 근속년수 대비 같은 업무를 한 비중이 높다면 이직률이 높을 것이다.
- 근속년수 대비 현재업무년차 비중 산출 후 분포 확인
- 결측에 대하여 0 대체
- Role_Company 3개의 범주로 그룹화 후 이직률 산출
df['Role_Company'] = df['YearsInCurrentRole'] / df['YearsAtCompany']
df['Role_Company'].fillna(0, inplace =True)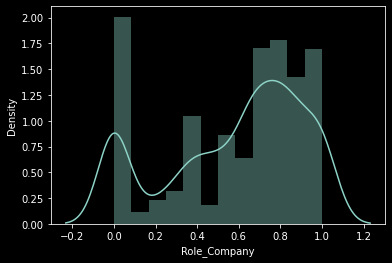

- 근속년수 대비 같은 일 을 오래한 경우 이직률이 낮다.
가설3) 야근을 많이 해도 급여인상률이 높다면 이직률이 낮을 것이다.
- 야근 여부에 따른 이직률 현황 파악
- 야근안하는 직원 - 연봉상승률이 높더라도 이직을 안하는 경향을 찾아보기는 힘듬
- 야근 Yes 직원 Data 분석
df_gp = df.groupby('OverTime')['Attrition'].agg(['count', 'sum'])
df_gp['ratio'] = round((df_gp['sum'] / df_gp['count']) * 100, 1)
df_gp_plot = df_gp.reset_index()
df_gp_plot = df_gp_plot[df_gp_plot['OverTime']=='Yes']
- 20%상승률 까지는 감소하는 듯하나 22%이상 상승하는 핵심인재의 경우 바로 이직한다.
3. ML 활용 이직 직원 예측
모델 학습 및 평가
- 'Age_gp', 'Role_Company_gp', 'Role_Company' 컬럼 제외
- 범주형변수 LabelEncoding
- RandomForestClassifier로 분류 예측 후, classification_report패키지를 활용하여 검증 지표 확인
- roc_auc_score산출 및 roc_curve 시각화
- 이직 관리프로그램 운영 모수..?
중요변수 파악 및 1위 변수 탐색
- Feature IMP 분석을 통한 중요변수 파악
- 1위 변수 TotalWorkingYears_gp 구간화 후 이직률 산출 → 경력이 낮을 수록 이직률이 높다.



- 경력이 낮을 수록 이직률이 높다.
결론
- 이직 가능성이 높은 직원 예측 및 관리 프로그램 운영(매 월 이직 가망 가능성 타겟 고객군 추출 및 관리프로그램 운영)
- 관리프로그램 운영 후 이직률 모니터링을 통한 성과 측정
- 매 월 Model에 Input하기 위한 Data mart 생성
위 교육 자료는 zerobase로부터 제공받아 작성되었습니다.
'📊 DATA ANALYSIS > 스터디노트' 카테고리의 다른 글
| [스터디노트] 숙박예약 수요 분석 (0) | 2024.05.24 |
|---|---|
| [스터디노트] 연관규칙분석을 통한 장바구니 분석(유통 데이터) (0) | 2024.05.23 |
| [스터디노트] 넷플릭스 선호 컨텐츠 분석 (0) | 2024.05.23 |
| [스터디노트] 선형 대수 (0) | 2024.05.23 |
| [스터디노트] GA(Google Analytics) 데이터 활용 유저분석 (0) | 2024.05.21 |